Blog
Parallelising python network jobs for a sweet speed boost.
Feb 10, 2013
Khan Academy offer all sorts of coach stats for student feedback. The interface allows you to see a large overview of your classes, or to get super granular and see how a particular student has struggled. One thing they don't offer, however, is the ability to see a students energy points over a particular time period. We wanted to send our coaches a report at the end of each week saying: This is how many energy points your students got this week, and this is how many modules they completed!
We currently do this manually, at https://www.khanacademy.org/class_profile/exercise-progress-over-time. This is obviously quite a tedious and timely process. To solve the problem, I was tasked with implementing a "coach stats tool" which would use the KA API to figure this all out and automatically (or manually) produce a report.
Firstly, I had never dealt with oAuth before, and learning to use it was incredibly interesting. Secondly, after all of that, as I dove in, I realized that to generate a report would take quite a few API queries. Heres what I thought had to be done:
I had to first gather each students email in the class, then in order to gather the energy points for a given student, I had to query /api/v1/user/exercises/ex_name/log for each ex_name in /api/v1/user/exercises (perhaps I could filter these by progress!=0, or not true in exercise_states.values()). Here is where I picked up the proficiencies too. I then had to add these points to the sum of the points variables in each log of each video in /api/v1/user/videos/video_id/log (I could use /api/v1/user/videos but I need to use the dt_start dt_end params...)
This ends up taking too long. I then thought about how I could make the process faster. The idea I settled on was to start fresh, and collect(and save) the data for each student in each pilot. We can just keep throwing data into our local database over time (using a background daemon on the server, for instance) and when a query is made we can fetch the info locally (taking a lot less time). The alternative is to queue the tasks in something like Rabbit MQ, and email the user when it's complete. I settled on going through each student and storing the requisite information in a json file. I stored the updated list of proficient exercises, and energy points, for every day they had been a member of KA. This took FOREVER, since a "day" was processed in a couple of minutes.
The next improvement I stretched for stemmed from the observation that each API query required at least 1 second to travel from here to KA, get processed, and return. This lead to the idea of multiprocessing the API requests. The problem is embarresingly parallel, I just mapped the exercise_log for each time period worth of API queries in parallel, and join the processes before moving onto the next time period. I didn't map the videos, since our students watch the videos offline and so often there are very few videos to process. Here's a screenshots of how that looked on my side:
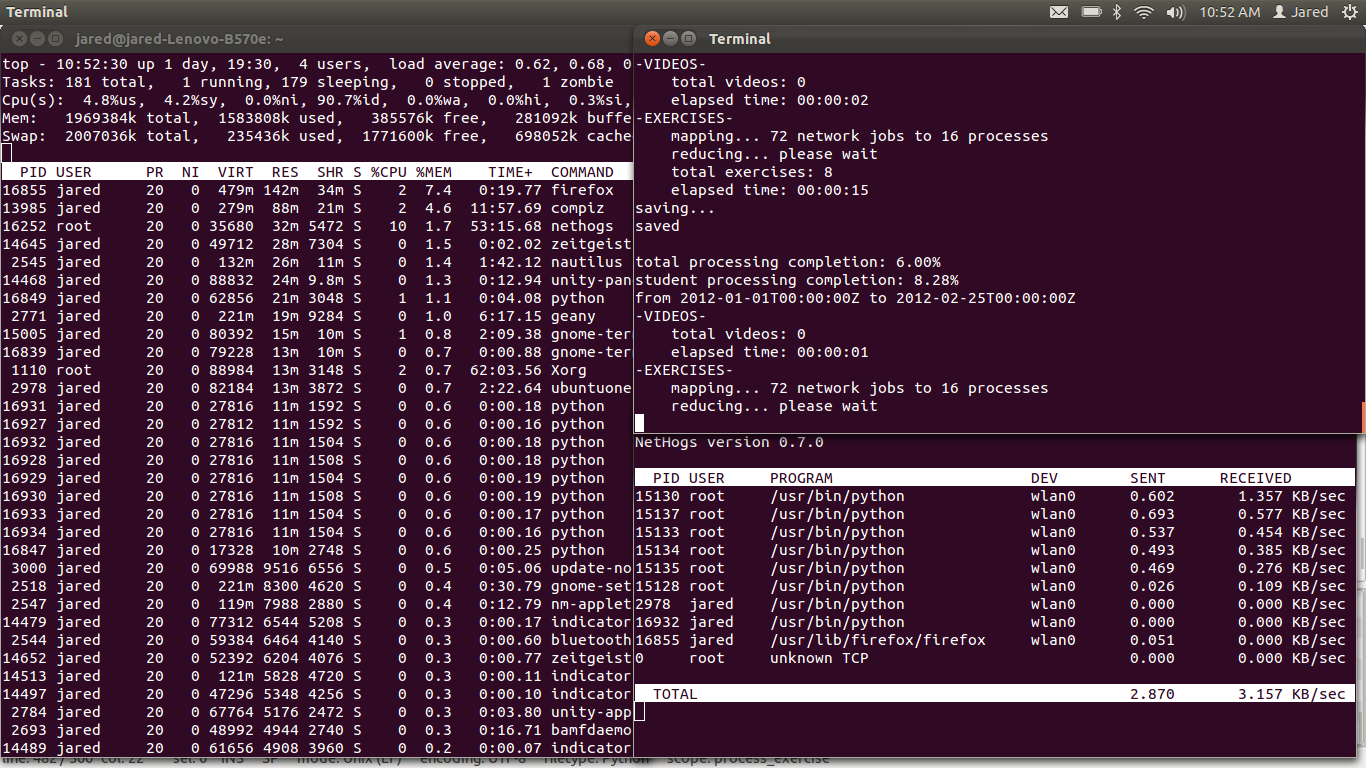
So this was finally feasible! I could finally see this as a functional tool. I got about a 6 times speedup out of it, and when we finally move our site to Django, I can see this becoming a valuable tool.
There is one final thing worth mentioning, a mistake, which I learned about the hard way. oAuth requires that you create a unique signiture called a no_once. This is something you send with each API query. I accidentally forgot to store the used up no_onces, and I was generating them in such a way that duplcates weren't exactly unlikely to occur. It wasn't until after hitting the API a couple thousand times that I realized the err of my ways!